2025-08-24 Weekly Notes

Intro
This is officially the first post in the new website, meaning that this is the first one written in Quarto Markdown format and not plain Markdown. I’ll make use of the advantages of this new website and organise the posts accordingly with headers that can be accessed from the right side of the window (desktop).
LCZ Classification
Geoclimate
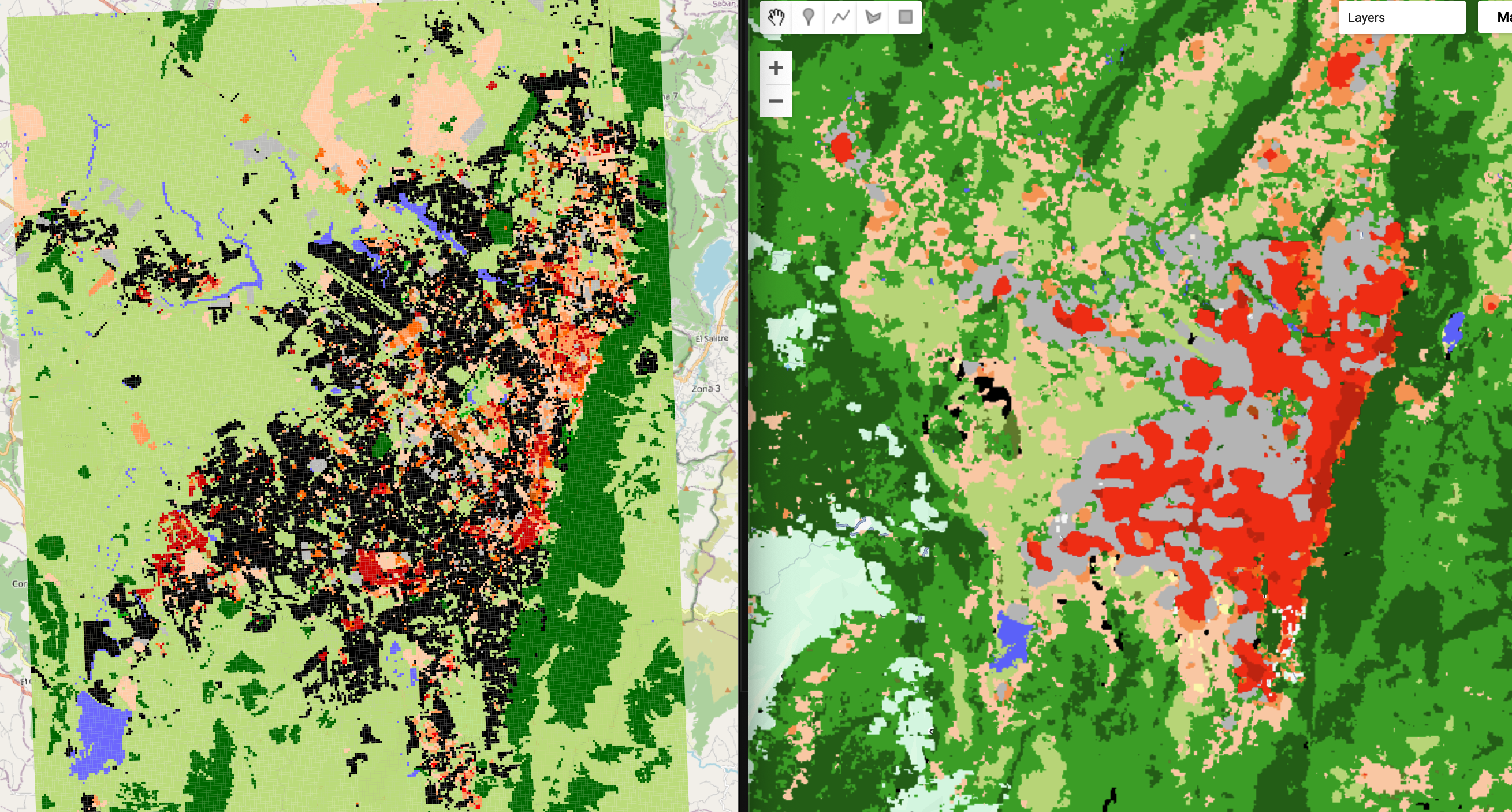
So, most of last week was spent working on getting the data for Local Climate Zones for cities. As said in the previous post, I used the GUPPD dataset from NASA to access the geometries of urban areas around the world. However, as I quickly realised when testing it for London, running Geoclimate for a whole city takes some time (15 hours to be precise). This is mostly a result of Geoclimate querying OSM data for a limited size for a given location, which meant that I had to tile the boundaries of cities to less than 1000 km2 (15 tiles in London). This is variable for each city and due to the CRS of the OSM, I decided to tile in unprojected coordinates so each tiles is 0.25x0.25 degrees, ensuring that even in the equator (looking at you Bogotá!!) the tiles do not surpass the 1000 km2 limit.
The second problem I encounter was that GUPPD has >300k cities, which is a lot and given the time it takes to calculate LCZs with Geoclimate, I decided to trim the dataset to cities with only more than 1M inhabitants, which resulted in only 515 cities. This is still a lot of cities to process, but it is manageable.
So, I left the script working for the whole long weekend expecting to find all the LCZs for major cities, but I found that some cities did not have any results and it took me a while to find out why because Geoclimate is written in Java but I am excuting it as a subprocess in Python, so I couldn’t see the error messages. With the help of Gemini, I found that my allocated /temp directory was full and Geoclimate couldn’t create the spatial databases based on OSM features. Now, that is sorted and it is running in parallel to speed up the process.
EO Foundation Models
In parallel to Geoclimate, I started getting the data for the predictors in this project. Earlier this year I had used the AlphaEarth model from Google to make some PCAs of London using their v2 of the embeddings. I had used XEE to convert directly in Python the ImagCollections to Numpy Arrays for easier processing in DL models. So I resumed that and based on the boundaries from GUPPD, I created a script to download only the embeddings matching the areas covered by the LCZ classes from Geoclimate. I decided on this approach instead of downloading all the tiles from Google Earth Engine because I didn’t want to use pixels from non-urbanised areas, which is most of the world. In addition to this, I tried to do something similar using the embeddings from TESSERA, where I only request those that match the boundaries from the Geoclimate classification, but I found some bugs in the Python API. Then I realised that it’s better to use the development version of TESSERA, instead of the one in PyPi. But, I’m still working on that.
Weekly Objectives
- Rasterise and co-register the LCZ classification from Geoclimate using the projection of the FM embeddings (AlphaEarth or TESSERA)
- Figure out what the most efficient way to get the embeddings from TESSERA is
- Resample the embeddings to the same resolution as the LCZ classification from Geoclimate (100x100m)
- Define the model to be used for the classification
Visualization
Reuse
Citation
@misc{c._zúñiga-gonzález2025,
author = {C. Zúñiga-González, Andrés},
title = {2025-08-24 {Weekly} {Notes}},
date = {2025-08-24},
url = {https://ancazugo.github.io/posts/2025-08-24-weekly-notes.html},
langid = {en}
}